

何千もの本物の人間の声 —— さまざまな年齢、アクセント、言語 —— がどんな響きなのか気になったことがあるなら、まさにそのためのデータセットがあります。Mozilla Common Voice と呼ばれ、世界最大級のオープンな録音音声コレクションのひとつです。
世界中の人々が自発的に文章を声に出して読み上げ、その録音を寄贈しています。その成果は、巨大で多言語にわたる本物の声のライブラリ —— 誰でも自由に使えるものです。
ただ、ひとつだけ問題があります。実際にそれをブラウズするのは難しいのです。
データセットは巨大なのに、ツールは追いついていない
Common Voice には数十の言語にわたる数百万もの音声クリップが含まれています。これに目を通すには、通常は数 GB のデータをダウンロードし、メタデータファイルを解析するスクリプトを書き、自前の再生パイプラインを用意する必要があります。あなたが開発者ならそれで構いませんが、それ以外のすべての人 —— 研究者、言語学者、プロダクトチーム、ただデータがどんな響きなのか聞いてみたい好奇心旺盛な人 —— を締め出してしまいます。
私たちは、これは惜しい機会の損失だと考えました。
そこで私たちは Common Voice Explorer を作りました
Common Voice Explorer は、このデータセットをブラウザ上で直接ブラウズできるシンプルなウェブツールです。ダウンロードも、スクリプトも、設定も不要です。
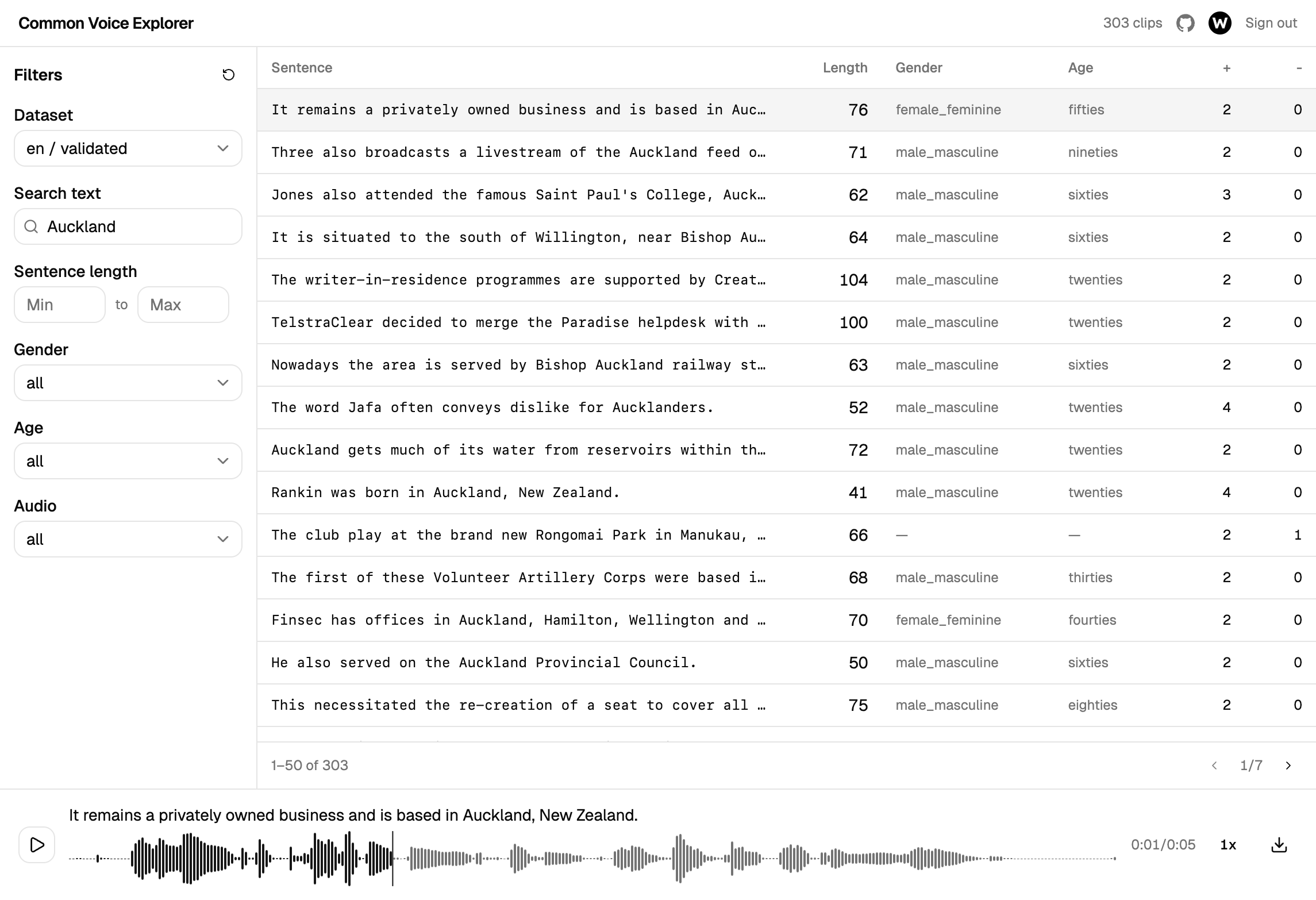
できることは次のとおりです。
- 文章で検索 —— 単語やフレーズを入力すると、それを含むクリップを即座に見つけられます
- 話者でフィルタリング —— 性別、年齢層、言語で結果を絞り込めます
- 長さでフィルタリング —— 必要に応じて、短い文章や長い文章を探せます
- すぐに再生 —— 任意のクリップをクリックすると、視覚的な波形とともに再生し、再生速度を調整したり、早送りや巻き戻しができます
- クリップをダウンロード —— 個々の録音をオフラインでの確認用に保存できます
音楽ライブラリをブラウズするような感覚になるよう設計されています。ただし曲の代わりに、世界中の本物の人々による本物の音声を探索するのです。
これは誰のためのもの?
正直に言えば —— 音声データに興味のある、あらゆる人のためのものです。
- 研究者 —— 発話パターン、アクセント、言語の多様性を研究する人
- プロダクトチーム —— 本格的に取り組む前に、Common Voice が自分たちのニーズに合うかを評価したい人
- 言語学者や教育者 —— 本物の口語の例を探している人
- 音声 AI の作り手 —— データ品質をすばやく確認したい人
- あらゆる人 —— 異なる人々が同じ文章をどう言うのかを聞くのが、ただ単に面白いと思う人
使うのに技術的な知識は必要ありません。検索バーを使い、再生ボタンをクリックできるなら、それで十分です。
なぜ私たちにとって大切なのか
WaveKat では、私たちは小規模ビジネスのための音声 AI ツールを作っています。この取り組みは高品質な音声データに支えられています。Common Voice はこの分野で最も重要なオープンリソースのひとつであり、それをより使いやすくすることは、エンジニアだけでなく、すべての人に恩恵をもたらすと私たちは信じています。
オープンデータは、人々が実際にそれを探索できてはじめて価値を持ちます。私たちが埋めたかったのは、まさにその隔たりです。
試してみる
Common Voice Explorer は commonvoice-explorer.wavekat.com で公開中です。GitHub でサインインし、利用規約に同意すれば、すぐに探索を始められます。
まず実際の動作を見てみたい方のために、短い YouTube のデモもあります。